こんにちは、もーすけです。
本日はKubernetesのノード障害が起きたときのPodの挙動について確認します。
いままで、ノード障害が起きたときのPodの挙動、スケジューリングについて誤った認識をしていました。
お恥ずかしい限りなのですが、同じような誤った認識をしているかたに向けて確認したことを解説します。
概要
まずはじめに、状況を説明します。Workerノード3台があって、アプリケーションが動作しているとします。 Worker#1がシャットダウンした、kubeletが停止した、ネットワーク的に疎通ができなくなったなどが起きたときに、その上で動いていてPodはどうなるの?という話です。 感覚的にいうと、レプリカ数を維持するために他のノードに移って起動するんでしょ!、と思いたいところなのですが、実際はそれほど単純でもありません。 どのような動きをしていくのか、Deploymentを使ったケース、StatefulSetを利用したケースなどで確認します。
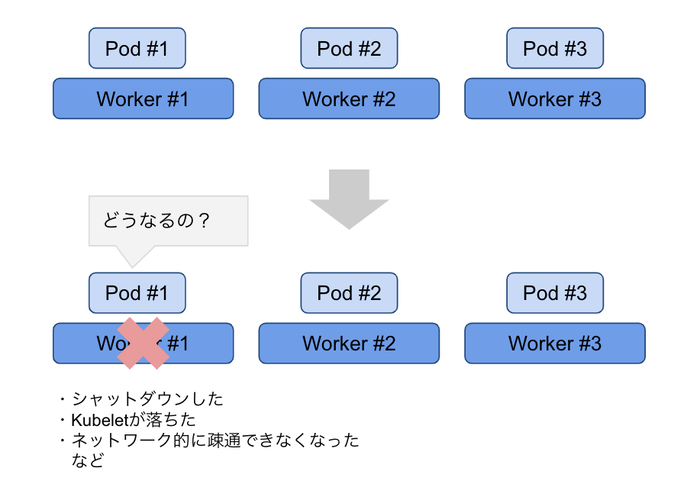
ノードをシャットダウンしたときに起きること(事象)
※このセクションでは事象を説明します。事象の解説については後述します。
ノードをシャットダウンしたり、kubeletを停止するとNodeのStatusはNotReadyとなります。
現在、Master x3, Worker x3で稼働しているクラスタですが。本ブログではMasterノードは気にしなくていいので、kubectl get node実行時にはWorkerのみ取り出すこととします。
$ kubectl get node --selector='node-role.kubernetes.io/worker'
NAME STATUS ROLES AGE VERSION
ip-10-0-163-234.ap-southeast-1.compute.internal Ready worker 9m6s v1.19.0+8d12420
ip-10-0-168-85.ap-southeast-1.compute.internal Ready worker 18h v1.19.0+8d12420
ip-10-0-184-189.ap-southeast-1.compute.internal Ready worker 9m28s v1.19.0+8d12420
また、Nginx DeploymentをReplicas=3で起動しておきます。Podが起動しているノードが重要です。よく確認しておきましょう。
ip-10-0-184-189.ap-southeast-1.compute.internal(以後、ip-10-0-184-189と記載)にひとつのPodが、ip-10-0-163-234.ap-southeast-1.compute.internal(以後、ip-10-0-163-234と記載)にふたつのPodが起動しています。
$ kubectl create deployment nginx --image=nginxinc/nginx-unprivileged:1.19 --replicas=3
deployment.apps/nginx created
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-5998485d44-44bsh 1/1 Running 0 32s 10.131.0.7 ip-10-0-184-189.ap-southeast-1.compute.internal <none> <none>
nginx-5998485d44-gg8h9 1/1 Running 0 32s 10.128.2.12 ip-10-0-163-234.ap-southeast-1.compute.internal <none> <none>
nginx-5998485d44-xcxpl 1/1 Running 0 32s 10.128.2.13 ip-10-0-163-234.ap-southeast-1.compute.internal <none> <none>
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 3/3 3 3 73s
それでは、Podがひとつ起動しているip-10-0-184-189のノードをシャットダウンします。
その後に、NodeのステータスおよびPodの動きに注目です。
$ ssh ip-10-0-184-189.ap-southeast-1.compute.internal
node# shutdown -h now
// 1分くらいたって ip-10-0-184-189 が NotReady になった
$ kubectl get node --selector='node-role.kubernetes.io/worker' -w
NAME STATUS ROLES AGE VERSION
ip-10-0-163-234.ap-southeast-1.compute.internal Ready worker 22m v1.19.0+8d12420
ip-10-0-168-85.ap-southeast-1.compute.internal Ready worker 18h v1.19.0+8d12420
ip-10-0-184-189.ap-southeast-1.compute.internal NotReady worker 23m v1.19.0+8d12420
このときのPodの状態を確認してみます。
実は、Pod(nginx-5998485d44-44bsh)は変わらずRunningのままです。
試しにこのPodへcurlでアクセスしてみますが当然応答は返しません。
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-5998485d44-44bsh 1/1 Running 0 10m 10.131.0.7 ip-10-0-184-189.ap-southeast-1.compute.internal <none> <none>
nginx-5998485d44-gg8h9 1/1 Running 0 10m 10.128.2.12 ip-10-0-163-234.ap-southeast-1.compute.internal <none> <none>
nginx-5998485d44-xcxpl 1/1 Running 0 10m 10.128.2.13 ip-10-0-163-234.ap-southeast-1.compute.internal <none> <none>
// IPで接続しているが、これはシャットダウンしたノードの上に稼働していたNginx
$ kubectl exec nginx-5998485d44-gg8h9 -- curl -I http://10.131.0.7:8080/
curl: (7) Failed to connect to 10.131.0.7 port 8080: No route to host
command terminated with exit code 7
// 他のPodへは疎通できることを確認
$ kubectl exec nginx-5998485d44-gg8h9 -- curl -I http://10.128.2.13:8080/
HTTP/1.1 200
Server: nginx/1.19.8
Date: Sat, 13 Mar 2021 05:29:51 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 09 Mar 2021 15:27:51 GMT
Connection: keep-alive
ETag: "604793f7-264"
Accept-Ranges: bytes
詳しい説明はあとでするとして、先に進みます。
5分経過後に変化がおきました。ip-10-0-184-189の上で動いていたnginx-5998485d44-44bshがTerminatingとなり、あらたにnginx-5998485d44-84zkgが起動しました。
ちなみに、このTerminatingのPod(nginx-5998485d44-44bsh) はこのままになってしまいました。
$ kubectl get node -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-5998485d44-44bsh 1/1 Terminating 0 14m 10.131.0.7 ip-10-0-184-189.ap-southeast-1.compute.internal <none> <none>
nginx-5998485d44-84zkg 1/1 Running 0 8s 10.128.2.24 ip-10-0-163-234.ap-southeast-1.compute.internal <none> <none>
nginx-5998485d44-gg8h9 1/1 Running 0 14m 10.128.2.12 ip-10-0-163-234.ap-southeast-1.compute.internal <none> <none>
nginx-5998485d44-xcxpl 1/1 Running 0 14m 10.128.2.13 ip-10-0-163-234.ap-southeast-1.compute.internal <none> <none>
起きたことの解説
そろそろ解説していきます。出来事としては理解できましたでしょうか。
事象的には、ノードをシャットダウンしてもすぐに、ノード上のPodは再スケジューリングされないということです。
ノードをシャットダウンした後、node_lifecycle_controller(Kubernetesのコントロールプレーンの機能のひとつ)は、KubeletがNode情報を更新しなくなったことを検知して、NodeのStatusを変更します。node_licecycle_controller.go の monitorNodeHealth() あたりが担当しています。
このときに、ノードに対して同時に key: node.kubernetes.io/unreachable のTaintを付与します。
$ kubectl describe node ip-10-0-184-189.ap-southeast-1.compute.internal
...
Taints: node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unreachable:NoSchedule
...
Podは作成時に、自動的にあるtolerationsが付与されています。 Kubernetesでは、DefaultTolerationSecondsというAdmission Controllerがデフォルトで動作しています。Podの作成時に、下に紹介するtolerationsを付与します。
$ kubectl get pod -o yaml anypod
...
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
このtolerationSecondsはデフォルトでは300秒に設定されており、300秒経ってもノードが復旧しない場合(Taintが外れない場合)、PodがEviction(強制退去)され別のノードにスケジュールされるという仕組みです。
そのため、ノードのシャットダウン後5分間(300秒)Podが再スケジューリングされなかったのはそのためです。
公式ドキュメントの「TaintとToleration」を改めて確認しておきましょう。
ちなみに、tolerationSecondsはkube-apiserverの起動時にオプションとして指定することが可能です。--default-not-ready-toleration-seconds, --default-unreachable-toleration-seconds で設定できます。詳しくはこちらのドキュメントをも確認しましょう。
しばらくPodがRunningであった理由
5分後に別のノードへと移りましたが、その間PodはRunningのままでした。
PodにCurlでアクセスをしても応答が返ってきませんでしたが、なぜRunningだったのでしょうか。
これは、Kubeletが停止しているからかと思います。PodのステータスはKubeletが更新しますが、そもそもノードのシャットダウンによってKubeletが停止しているのでPodのステータスの更新もできずにスタックしてしまっていると思っています。もし間違えていたらご指摘ください。
PodがTerminatingのままの理由
5分経過後、PodはTerminatingに変移し、別のPodが起動しました。
しかし、PodはTerminatingのままです。時間が経ってもPodが消えずに残ったままになります。
これもKubeletが起動していないからかと思います。Podの削除後、Kubeletがプロセスとして終了させますが、起動していないのでKubeletの確認待ちというステータスで止まっているということです。
解消する方法としては、Podの強制削除やNodeオブジェクトの削除することなどがあります。
Nodeが一定時間で復旧する場合
Nodeが一定時間で復旧する場合はどうでしょうか?
たとえば、シャットダウンではなく再起動です。#shutdown -r now と再起動させたときの動作について考えます。5分以内(tolerationSeconds以内)にノードが復旧すれば、key: node.kubernetes.io/unreachable のTaintが外れ、Podが強制退去されることなく再開します。同じノードで起動し続けるということですね。
仮にですが、tolerationSecondsが極端に短かったとします。ノードの再起動や一時的なノード障害であっても、Podは別のノードに移動します。一方で、Podが一部のノードに偏ってしまう可能性が高まってしまうのでトレードオフです。十分に注意して起きましょう。
StatefulSetを利用する場合の考慮
今までの例ではNginx Deploymentを使っていましたが、StatefulSetを利用している場合は、また別の考慮ポイントがあります。Deploymentは、StatefulSetと異なり、Podのレプリカ数について厳密性を求めていません。
あるPodがTerminatingになれば他のPodの起動が可能ですが、StatefulSetは公式ドキュメント(「StatefulSet Podの強制削除」)に記載がある通り、クラスター内で実行されている特定のIDを持つ最大1つのPodがいつでも存在することを保証します。つまり、Terminatingステータスになっても、完全に削除されたことを確認できるまでは、Podを作成することはできません。
StatefulSetコントローラーは、StatefulSetのメンバーの作成、スケール、削除を行います。それは序数0からN-1までの指定された数のPodが生きていて準備ができていることを保証しようとします。StatefulSetは、クラスター内で実行されている特定のIDを持つ最大1つのPodがいつでも存在することを保証します。これは、StatefulSetによって提供される最大1つのセマンティクスと呼ばれます。
StatefulSetでPodがTerminatingでスタックした場合の解消方法として下記が公式ドキュメントにも書かれています。
例としては、kubectl delete pod xxxx --forceで強制削除すれば、ノードが復旧できない状況でも最悪リスケジュールできます。
- (ユーザーまたはNode Controllerによって)Nodeオブジェクトが削除されるとき
- 応答していないNodeのkubeletが応答を開始し、Podを終了してapiserverからエントリーを削除するとき
- ユーザーによりPodを強制削除するとき
tolerationSeconds前にPodを削除した場合
ここまで見てきたように、NodeをシャットダウンしてもPodがリスケジュールされないのは、KubeletによってPodのステータスが変更されないことにありました。 もし、StatefulSetではなくDeploymentを利用していてステートレスなアプリケーションであれば、tolerationSecondsを待つ前にPodを削除してしまって対処することも選択としてとれます。
ノードオブジェクトの削除した場合
ノードをシャットダウンではなくて、Kubernetesからノードオブジェクトを削除したらどうなるでしょうか?
kubectl delete node worker-xxxxなどでノードオブジェクトを削除した場合は、前に見てきたようなノードの復旧・Kubeletの復旧を待つことがないので、比較的すばやくPodは再スケジューリングされます。
まとめ
はい、以上に見てきたように、KubernetesのWorkerノードが停止した際、障害が発生した際の挙動を見てきました。 Kubernetesでは、Podの偏りを回避するなどの目的もあり、ノードが停止したからといってすぐに別のノードに再スケジューリングされるわけではありません。Podを削除したときの挙動とは異なるので十分に注意しましょう。 本番環境での運用を見据えると、ノードが停止したときの対応策についても十分に検討しておく必要がありそうです。その際もDeploymentなのかStatefulSetなのか、利用しているワークロードの種類によってもアプローチが異なります。動きを正しく理解しておくことで、より適切な対策が打てるようになるのではないかと思います。
