こんにちは、もーすけです。
なんとなくあいまいに理解していなかった、「マルチAZ環境に構築したKubernetesで、PVをマウントしたPodがどのノードにスケジュールされるのか?」について軽く調べてみました。ほぼ自分のメモなので、間違っているところもあるかもしれません。
前提
本ブログは、AWS環境にマルチAZで構成した(東京リージョンで、a/c/dゾーンを利用)、Kubernetes 1.23を前提とします。 ブロックストレージにはEBSを、ファイルストレージにはEFSを使うこととします。EBSの作成には、EBS CSI driverを利用、EFSのマウントにはAmazon EFS Driverを使うこととします。
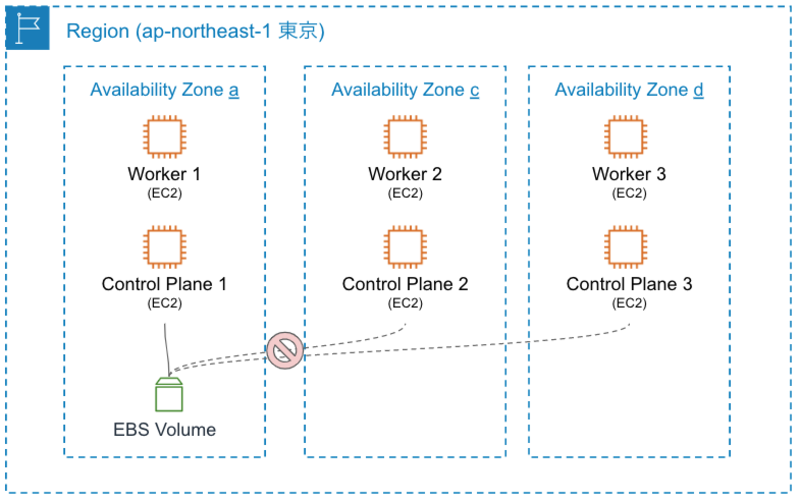
また、AWSを普段使っている人にとってはあたりまえのことだと思いますが、AWSで利用できるブロックストレージのEBSは、AZをまたいでEC2インスタンスにアタッチすることはできない、ということを前提に話をすすめます。
雰囲気
EBSボリュームは、AZをまたいでEC2インスタンスにアタッチできないため、Podのスケジューリングもいい感じにEBSボリュームがアタッチ可能なノードを選んでくれそうですよね。
経験則的にはそうだったのですが、ほんとうにそうなのか?どうしてそうなのか?(いままでちゃんと確認してなかったので)確認しようと思ったところです。
ポイント
1. Nodeにzoneとregionのラベルが付与される
Kubernetesにジョインしているノードに、リージョンやゾーン情報がラベルとして付与されることが大事です。結局、PVがどのリージョン/ゾーンにあって、Podをどこに配置するか決定しなければならないからです。
cloud-controller-manager は、ノードにリージョンやゾーン情報が付与しますし、CSI Driverもノードに対してラベルを付与することがあります。topology.ebs.csi.aws.com/zone は、CSI Driverが付与したものです。
failure-domain.beta.kubernetes.io/region と failure-domain.beta.kubernetes.io/zoneは、Kubernetes 1.17以降でDeprecatedになっているので注意です(公式ドキュメント)。
$ kubectl get node worker1 -o yaml | grep -e "zone" -e "region"
failure-domain.beta.kubernetes.io/region: ap-northeast-1
failure-domain.beta.kubernetes.io/zone: ap-northeast-1a
topology.ebs.csi.aws.com/zone: ap-northeast-1a
topology.kubernetes.io/region: ap-northeast-1
topology.kubernetes.io/zone: ap-northeast-1a
2. ボリュームがどのゾーンで作成されるか
つぎのStorageClassとPVCのマニフェストを使ってPVCを作成します。PVが作成されるとともに、EBS CSI driverによって、ボリューム実体であるEBSが作成されます。
どのゾーンにEBSが作成されるかは重要なポイントだと思います。ここでは検証でわかりやすくするために、volumeBindingMode: Immediate としました。
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gp2-csi-immediate
provisioner: ebs.csi.aws.com
parameters:
encrypted: 'true'
type: gp2
reclaimPolicy: Delete
allowVolumeExpansion: true
volumeBindingMode: Immediate
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 10Gi
storageClassName: "gp2-csi-immediate"
EBSが作成されるAZの指定は、StorageClassに設定できる allowedTopologies によってフィルタも可能です。
もし指定がなければ、EBS CSI driverの場合はAZをランダムで選択します。 AWSのAPIレベルではEBSの作成にAZ指定は必須ですが、EBS CSI driver側でランダムに決定する実装が入っていました (randomAvailabilityZone())。
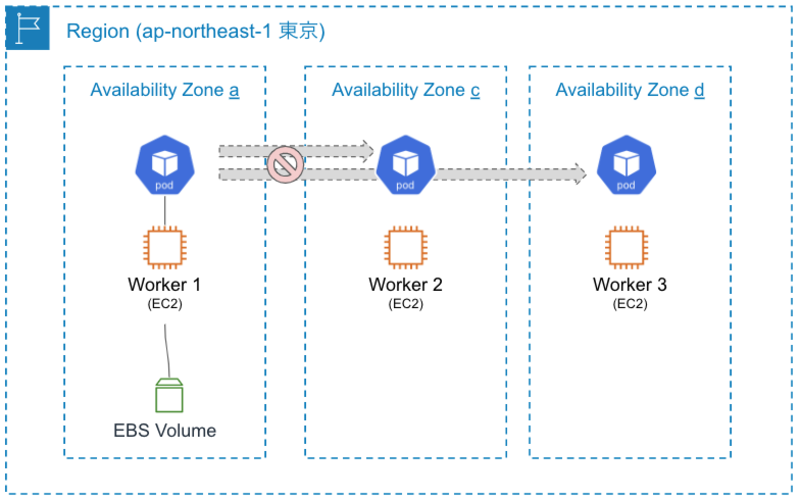
作成されたPVには、nodeAffinityが記述され、EBSが作成されたゾーンのノードにPodをスケジューリングするようになっていました。
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: ebs.csi.aws.com
...
spec:
...
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: topology.ebs.csi.aws.com/zone
operator: In
values:
- ap-northeast-1a
persistentVolumeReclaimPolicy: Delete
storageClassName: gp2-csi-immediate
volumeMode: Filesystem
3. Schedulerは、Podに紐づくボリューム設定を考慮する
Default Schedulerは、Podの配置先ノードを決定する際に、Podに紐づくボリュームの情報も考慮にいれます。
アプローチはいくつかあるのですが、2.ででてきた nodeAffinity は一番わかりやすいですね。
Scheduler PluginのVolumeBindingにて、ノードが要求したボリュームをもっているか確認します。ここで、PV側のnodeAffinityをみるようです。
ほかにも、Scheduler PluginのVolumeZoneは、要求されたボリュームがゾーン要件を満たしているかどうかを確認します。
実装的にも、failure-domain.beta.kubernetes.io/region, failure-domain.beta.kubernetes.io/zone, topology.ebs.csi.aws.com/zone, topology.kubernetes.io/region, topology.kubernetes.io/zoneのラベルが、ノードとPV側でマッチするかをみているようでした。
 GitHub
GitHub
EFSの場合
ちなみに、RWXでゾーンをまたいでマウントできるEFSの場合は、とくに nodeAffinity も対象のラベルが付与されていませんでした。なので、Podは別ゾーンのノードに配置されることもありえますね。
使ったのは、Amazon EFS CSI です。
以下は、Amazon EFS Driverによって作成したPV情報です。
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: efs.csi.aws.com
creationTimestamp: "2022-05-31T02:02:01Z"
finalizers:
- kubernetes.io/pv-protection
name: pvc-84622e94-b10c-485f-8397-38a88ad1cb77
resourceVersion: "372677"
uid: ecd31ae1-e97e-4150-b06b-61b106977cd4
spec:
accessModes:
- ReadWriteMany
capacity:
storage: 5Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: my-efs
namespace: default
resourceVersion: "372666"
uid: 84622e94-b10c-485f-8397-38a88ad1cb77
csi:
driver: efs.csi.aws.com
volumeAttributes:
storage.kubernetes.io/csiProvisionerIdentity: 1653960834425-8081-efs.csi.aws.com
volumeHandle: fs-0a51f26d89a5046ce::fsap-0ddc3edcf81a2dc97
persistentVolumeReclaimPolicy: Delete
storageClassName: efs-sc
volumeMode: Filesystem
status:
phase: Bound
マルチAZ環境での利用
耐障害性の観点で、マルチAZ環境でKubernetesクラスタを構築することは、当然役に立つものではありますが、ステートを持つアプリケーションにおいてはしっかりこの点も考えておかなければならないです。コンテナだからという問題ではないですが。 ノード障害を考えても、各AZに2台以上のWorkerノードを準備しておくべき場面もでてきますね。
