こんにちは。@mosuke5です。
みなさん普段の監視はどのように行っていますか?Datadog使っていますか?
最近Datadogを触る機会が多いのですが、Datadogはobservabilityの3本柱ということで、メトリックとトレース(APM)とログ、この3つを統合した監視サービスであることを強くおしだしています。 3つの分野のそれぞれに対応したOSSやサービスは多いですが、統合されてシームレスに連携できる点はDatadogの非常に強いポイントと感じます。 さて、そんななかでDatadog APM (Application Perfomance Monitoring) が強力だったので紹介したいのと、その仕組みを探っていきましょう。
APMとはなにか、なぜ必要か
従来的な監視との違い
今回に至るまで、APMは名前は聞いたことがありましたが、実際に利用したことはありませんでした。 APMはApplication Performance Monigoringの略で、名前から想像ができる通りアプリケーションに関するモニタリングです。 アプリケーションのモニタリングというと、通常の監視となにも変わらないように思えるのですが下記の点で異なります。
- APM
- 専用のライブラリをアプリケーションに組み込んで、「実際のユーザからのリクエスト」に対するパフォーマンスやエラーを計測、監視する。
- 従来的なアプリケーションの監視 (※1)
- アプリケーションのプロセスが動いているか確認する。
- 外形監視として定期的に、アプリケーションにリクエストを発行して正常か確認する。
- あくまで実際のユーザのリクエストではなく、監視のためのリクエスト。
- アプリケーションが出力したログからエラーが出ていないか監視する。
※1: 「従来的なアプリケーションの監視」とは、私のAPMに出会う前のアプリケーションの監視の認識をもとに書いています。
なぜ必要か?
なぜAPMが必要なのでしょうか?
一番の理由はアプリケーションのパフォーマンスがビジネスにおいてより重要な役割を果たすようになってきたからでしょう。
そして、アプリケーションがどんどん複雑化していて、パフォーマンスの改善やエラーの特定が難しくなってきているからです。
このような状況にもかかわらず、APMを利用してみて感じたことなのですが、いかに今まで自らのアプリケーションの監視ができていなかったか痛感します。
それは、やはり今までは外側からしかアプリケーションを監視していなかったからです。
アプリケーションのことはアプリケーションが一番よく知っているわけで、内側から計測していかないといけません。
どのようなものか
具体的にどのようなメトリックを収集できるのか例をあげてみます。
- 時間ごとのリクエスト数、エラー数
- アプリケーションのレイテンシー
- エンドポイント毎のリクエスト数、レイテンシー、エラー率
- 各リクエストごとの処理時間、ボトルネック
とくに各リクエストごとの処理時間やボトルネックが追えるのが魅力的です。
下記は、あるリクエストでエラーが発生したときのAPMの画面です。どこの処理でなんのエラーがでているか簡単に追うことができます。またそのときのホストのリソース状況も同時に確認できます。
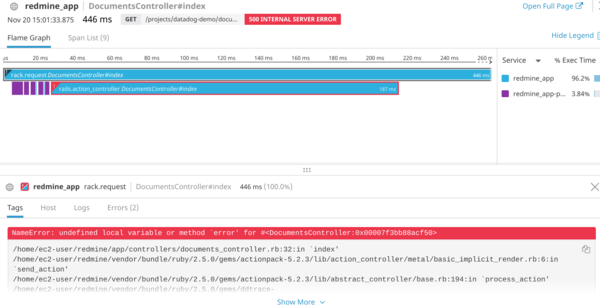
動画もありましたので、イメージをわいてもらうために掲載しておきます。
Datadog APMの導入
上のような素晴らしいことができるわけですが、Datadog APMの場合、導入も非常に簡単です。
このブログではあまり手順的な話にしたくないので、こちらも1分の動画がありましたので参考にしてください。
どうしてできるのか
ドキュメントのインストールの手順の通りで言えば、ライブラリを入れて、アプリケーションの設定ファイルに数行書くだけ。 それだけで、上のようなことができてしまうわけです。一見魔法のように見えるDatadog APMですが、どんな情報を取得しているのか気になります。
トレースの簡単な仕組み
トレース、トレーシングというと、最近では「分散トレーシング」という言葉で聞くことが多いと思いますが、 必ずしも分散システムやマイクロサービスのでなくてもトレースは実現できるし役に立ちます。 ひとつのモノリシックなアプリケーションの中での各処理もトレーシングを使ってみていくことができます。 (分散トレーシングに対してシングルトレーシングなんていったりするらしいです)
まずは、トレーシングの簡単な概要について説明します。
下記のような簡単な処理を行うWebアプリケーションの1つのリクエスト例に考えてみましょう。
- アプリケーションがリクエストを受け付けます
- コントローラがリクエストを処理をします
- コントローラは画面を表示するのに必要なデータをDBから取り出します
- ビューレンダリングをします
実際にどうやってトレースされていくのかというと、 下図のように3つのIDが振られて管理されていきます。 各処理に3つのIDをふることで親子関係を認識し、またここには書いてませんが、それぞれの処理の開始時間と終了時間がわかれば下記のような図が書けます。 こちらは簡単な例でしたが、Datadog APMではこのようなことを実際のアプリケーションに対して行ってくれます。
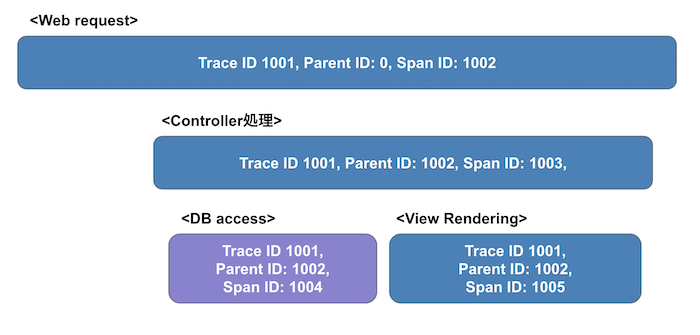
| 項目名 | 意味 |
|---|---|
| Trace ID | 一連のトレースを管理するID。この例でいうとすべて同じ。 |
| Parent ID | 親の処理のSpan ID。Parent IDが0のものは一番親でありはじめの処理。 |
| Span ID | それぞれの処理のID |
実際のトレースのログ
上で簡単な例として見ていきましたが、実際のアプリケーションでどのようになっているのでしょうか。 デフォルトの設定だとトレースのログの出力がされませんが、設定を変更してログファイルを出力させてみると理解ができますのでやってみます。 こちらの例は、Ruby on Railsで動いているRedmineに対してDatadog APMを導入したものです。
設定の変更
Datadogの設定において、下記のようにmy-custom.logにログを出力するようにしておきます。
f = File.new("my-custom.log", "w+")
Datadog.configure do |c|
c.use :rails
c.tracer log: Logger.new(f)
end
トレースログ
こちらが実際に、Redmineのトップページにアクセスしたときに出力されたログのはじめの部分です。 サンプルの例でみたものよりももっとたくさんの情報で構成されています。 データベースからの情報取得についてみてみると、実際に発行されたSQLもデータとして扱われています。 ゆえに、どのSQLの処理がボトルネックになっているか判断したりできるわけです。
Name: rack.request
Span ID: 4092285044422002896
Parent ID: 0
Trace ID: 5153016093792861274
Type: web
Service: redmine_app
Resource: WelcomeController#index
Error: 0
Start: 1574235569204547584
End: 1574235569259600128
Duration: 55052569
Allocations: 9632
Tags: [
system.pid => 12492,
language => ruby,
http.method => GET,
http.url => /,
http.base_url => http://xxxxx.ap-northeast-1.elb.amazonaws.com,
http.status_code => 200,
http.response.headers.content_type => text/html; charset=utf-8,
http.response.headers.x_request_id => a1c70291-36bd-41ad-bbb8-8ef1d1c6c2b0]
Metrics: [
_sampling_priority_v1 => 1.0],
Name: postgres.query
Span ID: 5781776840616204252
Parent ID: 4092285044422002896
Trace ID: 5153016093792861274
Type: sql
Service: redmine_app-postgres
Resource: UPDATE "tokens" SET "updated_on" = '2019-11-20 07:39:29.205854' WHERE "tokens"."user_id" = $1 AND "tokens"."value" = $2 AND "tokens"."action" = $3
Error: 0
Start: 1574235569208989952
End: 1574235569215289088
Duration: 6299193
Allocations: 26
Tags: [
active_record.db.vendor => postgres,
active_record.db.name => redmine,
out.host => xxxxx.ap-northeast-1.rds.amazonaws.com,
out.port => 5432]
Metrics: [ ],
| 項目名 | 意味 |
|---|---|
| Name | 処理の名前 |
| Span ID | それぞれの処理のID |
| Parent ID | 親のSpan ID。 |
| Trace ID | 一連の処理のトレースID |
| Resource | 実行されたアプリケーションのメソッド名やSQL |
| Start | 開始した時間 |
| End | 終了した時間 |
| Duration | 処理にかかった時間 |
分散トレーシングの場合
分散トレーシングまでは実施していないのですが、考え方は基本的に同じです。
他の異なるサービスにたとえばHTTP経由でアクセスする場合には、HTTPヘッダーにx-datadog-trace-idやx-datadog-parent-idを追加することで、他のシステムの処理であっても紐づけすることができます。
そのため、下記のService Mapと呼ばれる分散システム間でのマッピングがかけるわけです。
また、分散トレーシングが本当に必要になるのはマイクロサービスの世界でのことでしょう。 マイクロサービスも非常に誤解の多い言葉であり概念です。SockShopというマイクロサービスの練習をするためのアプリケーションでハンズオンしてみるとよいでしょう。 以下のブログの中では、JaegerというOSSの分散トレーシングのツールを利用する場面もでてきます。
まとめ
APMの魅力や仕組みについて理解できましたでしょうか。
Datadog APMを体験すれば、アプリケーションをいかに理解していないか痛感することもあると思います。
また、トレーシングときくと最近は分散トレーシングの文脈で聞くことが多いですが、普段身近に扱っているもっと小規模なシステムでも十分にトレーシングの考え方を応用できます。
自分自身が動かしているアプリケーションの運用状態を本当に理解できているか、監視・計測できているか、あらためて問いかけてみましょう。
