※本記事は、著者であるZhimin Tangの許可をとって翻訳した記事となります。(原文)
また本記事の内容は、2020/12/11のAliEaters Tokyo #16にて発表しており、スライドは以下です。
概要
2015年以来、Alibaba Cloud Container Service for Kubernetes(ACK)は、Alibaba Cloud上でもっとも急速に成長しているクラウドサービスの1つです。今日では、ACKは多数のAlibaba Cloudの顧客にサービスを提供しているだけでなく、Alibabaの社内インフラストラクチャやその他多くのAlibaba Cloudサービスをサポートしています。
世界的なクラウドベンダーが提供する他の多くのコンテナサービスと同様に、ACKでは信頼性と可用性が最優先事項となっています。これらの目標を達成するために、セルベースでグローバルに利用可能なプラットフォームを構築し、数万個のKubernetesクラスタを稼働させています。
今回のブログ記事では、クラウドインフラ上で大量のKubernetesクラスタを管理した経験と、その基盤となるプラットフォームの設計についてご紹介します。
導入 (Introduction)
Kubernetesは、さまざまなワークロードを実行するための事実上のクラウドネイティブプラットフォームとなっています。たとえば、図1に示すように、Alibaba Cloudではアプリケーションオペレータだけでなく、より多くのステートフル/ステートレスアプリケーションがKubernetesクラスタで実行されるようになっています。 Kubernetesを管理することは、インフラエンジニアにとって常に興味深く深刻なテーマです。Alibaba Cloudのようなクラウドプロバイダーといえば、必ずスケールの問題を指摘します。大規模Kubernetesクラスタ管理とは?過去に、10,000ノードでKubernetesを管理するベストプラクティスを発表してきました。確かに、それは興味深いスケールの問題です。しかし、スケールにはもうひとつの側面、つまりクラスタの数があります。
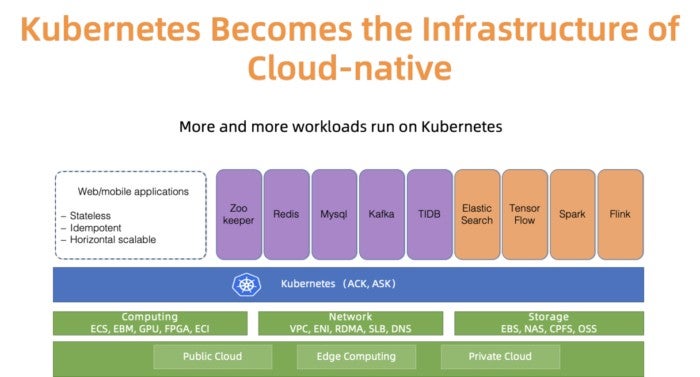
図1: Kubenetes ecosystem in Alibaba Cloud
私たちは、多くのACKユーザーとクラスターのスケールについて話をしてきました。ほとんどのユーザーは、障害の拡大の対策(blast radiusへの対応)、異なるチームのためのクラスタの分離、テストのための一時的にクラスターを作成・削除するなどの正当な理由から、数百ではないにしても数十個の小規模または中規模のKubernetesクラスタを実行することを好んでいます。おそらく、ACKがこのような使用用途で顧客をグローバルにサポートすることを目指していた場合、20以上のリージョンにまたがる多数のクラスタを確実かつ効率的に管理する必要があるでしょう。 (解説:つまりひとつの巨大なクラスタではなく、小さなクラスタを大量に管理することになるということ。)
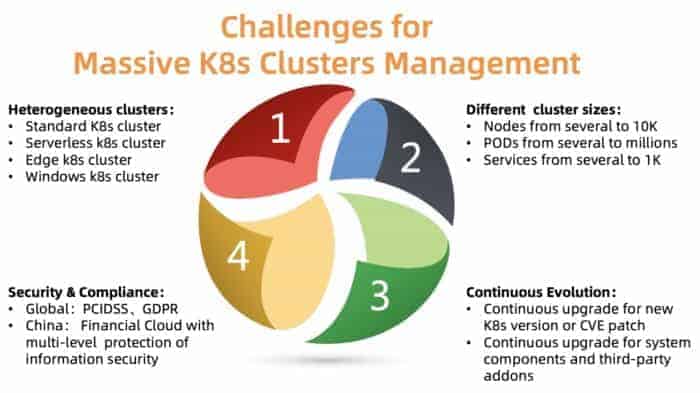
図2: The challenges of managing massive number of Kubernete clusters
クラスターを大規模に運営する上での大きな課題は何でしょうか。図2にまとめたように、取り組むべき大きな課題は4つあります。
Heterogeneous clusters
ACKは、標準、サーバーレス、Edge、Windows、その他いくつかのクラスタを含む、さまざまなタイプのクラスタをサポートする必要があります。異なるクラスタは、異なるパラメータ、コンポーネント、ホスティングモデルを必要とします。お客様の中には、ユースケースに合わせたカスタマイズを必要とされる方もいらっしゃいます。
Different cluster sizes
異なるクラスタは、数ノードから数万ノード、数ポッドから数千ポッドまで、サイズが異なります。これらのクラスタのコントロールプレーンに必要なリソースは大きく異なります。リソースの割り当てが悪ければ、クラスタの性能を損ねたり、故障の原因になったりする可能性があります。
Different versions
Kubernetes自体の進化は非常に速く、数ヶ月ごとに新しいリリースサイクルがあります。顧客は常に新しい機能を試したいと思っています。そのため、本番のワークロードは安定したバージョンで実行しながら、新しいバージョンのテストワークロードを実行することがあります。この要件を満たすために、ACKは継続的に新しいバージョンのKubernetesを顧客に提供し、安定版をサポートする必要があります。
Security compliance
クラスターは異なる地域に分散しています。したがって、それらは異なるコンプライアンス要件に準拠しなければなりません。たとえば、ヨーロッパのクラスターはGDPRに従う必要があり、中国の金融クラウドは追加の保護レベルを持つ必要があります。これらの要件を達成できないことは、顧客に大きなリスクをもたらすことになるため、選択肢にはなりません。
設計 (Design)
Kube-on-kube and cell-based architecture
セルベースのアーキテクチャは、集中型アーキテクチャと比較して、単一のデータセンターを超えて容量をスケーリングしたり、ディザスタリカバリ領域を拡大したりする場合に用いられます。
Alibaba Cloudは、世界中に20以上のリージョンを持っています。各リージョンは複数の利用可能ゾーン(AZ)で構成されており、通常はデータセンターにマッピングされています。大規模なリージョン(HangZhouリージョンなど)では、何千もの顧客のKubernetesクラスタがACKによって管理されていることがよくあります。
ACKはこれらのKubernetesクラスタをKubernetes自体を使って管理していますが、これはつまり、顧客のKubernetesクラスタのコントロールプレーンを管理するためにメタKubernetesクラスタを実行していることを意味します。このアーキテクチャは、Kube-on-kube(KoK)アーキテクチャとも呼ばれています。KoKはクラスタのロールアウトを容易にし、決定論的なものにするので、顧客のクラスタ管理を簡素化します。さらに重要なのは、ネイティブのKubernetesがそれ自体で提供している機能を再利用できるようになったことです。たとえば、デプロイメントを使ってAPIサーバを管理したり、etcd演算子を使って複数のetcdを運用したり。ドッグフーディングには常に楽しみがあります。
1つのリージョン内で、ACKの顧客の成長をサポートするために、複数のメタKubernetesクラスタをデプロイします。各メタクラスタをセルと呼んでいます。AZの障害を許容するために、ACKは1つのリージョン内でマルチアクティブなデプロイをサポートしていますが、これはメタクラスタが顧客のKubernetesクラスタのマスターコンポーネントを複数のAZに分散し、アクティブアクティブモードで実行することを意味します。マスターコンポーネントの信頼性と効率性を確保するために、ACKは異なるコンポーネントの配置を最適化し、API Serverとetcdが互いに近接してデプロイされるようにしています。
このモデルにより、Kubernetesを効果的に、柔軟に、そして確実に管理することが可能になりました。
Capacity planning for meta cluster
上でも述べたように、各リージョンでは、顧客数が増えればメタクラスタの数も増えていきます。しかし、いつになったら新しいメタクラスタを追加しなければならないのでしょうか?これは典型的なキャパシティプランニングの問題です。一般的には、既存のメタクラスタが必要なリソースを使い果たしたときに、新しいメタクラスタがインスタンス化されます。
ネットワークリソースを例に考えてみましょう。KoKアーキテクチャでは、顧客のKubernetesコンポーネントはメタクラスタ内のPodとしてデプロイされます。コンテナネットワークを管理するために、Alibaba Cloudが開発した高性能コンテナネットワーキングプラグインであるTerway(図3)を使用します。これは、豊富なセキュリティポリシーのセットを提供し、Alibaba Cloud Elastic Networking Interface (ENI)を使用してユーザーのVPCに接続できるようにしています。メタクラスタ内のノード、ポッド、サービスにネットワークリソースを効率的に提供するためには、メタクラスタVPC内のネットワークリソースの容量と利用率に基づいて慎重に割り当てを行う必要があります。ネットワークリソースが尽きそうになったら、新しいセルを作成します。
また、コスト要因、密度要件、リソースクォータ、信頼性要件、統計データを考慮して、各メタクラスタ内の顧客クラスタ数を決定し、新たにメタクラスタを作成するタイミングを決定します。小さなクラスタはより大きなクラスタに成長する可能性があるため、クラスタ数が変わらない場合でもより多くのリソースを必要とすることに注意します。私たちは通常、各クラスタの成長を許容するために十分な余剰リソースを残します。
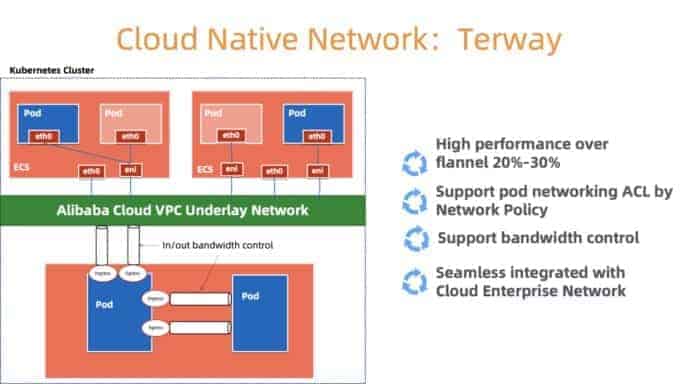
図3: Cloud Native network architecture of Terway
Scaling the master components of customer clusters
Kubernetesのマスターコンポーネントのリソース要件は固定ではありません。数は、ノード数、クラスタ内のポッド数、およびAPIServerと相互作用するカスタムコントローラとオペレータの数に関連しています。
ACKでは、各顧客のKubernetesクラスタはサイズと実行時の要件が異なります。すべてのユーザー クラスターのマスター コンポーネントをホストするために同じ構成を使用することはできません。大きな顧客に対して誤って低いリソース要求を設定してしまうと、パフォーマンスが悪くなる可能性があります。すべてのクラスタに対して保守的な高いリソース要求を設定すると、小さなクラスタではリソースが無駄になります。
信頼性とコストのトレードオフを慎重に処理するために、ACKはタイプベースのアプローチを使用します。具体的には、小、中、大の異なるタイプのクラスタを定義します。クラスタのタイプごとに、個別のリソース割り当てプロファイルが使用されます。各顧客クラスタは、マスターコンポーネントの負荷、ノード数、およびその他の要因に基づいて識別されるクラスタタイプに関連付けられています。クラスタタイプは時間の経過とともに変更される可能性があります。ACKは関心のある要因を常に監視しており、それに応じてクラスタ・タイプを変更させることがあります。クラスタタイプが変更されると、基礎となるリソース割り当ては、ユーザの中断を最小限に抑えて自動的に更新されます。
私たちは、移行をよりスムーズかつ費用対効果の高いものにするため、より細かいスケーリングとインプレースタイプの更新の両方に取り組んでいます。
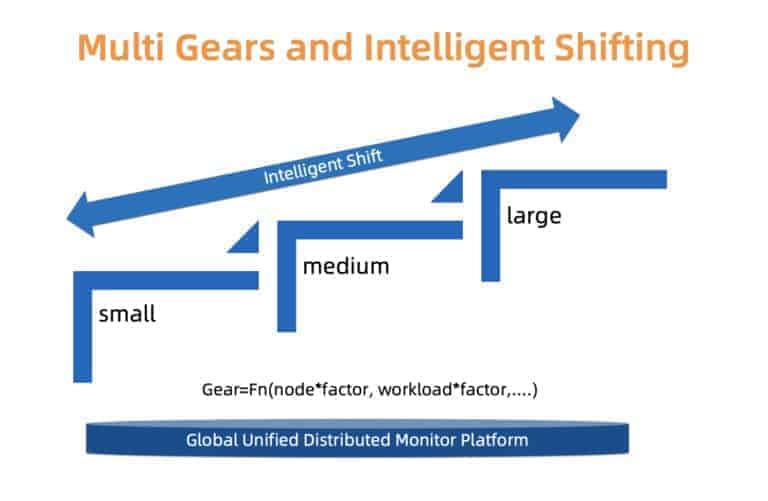
図4: Multi gears and intelligent shifting
Evolving customer clusters at scale
これまでのセクションでは、大量のKubernetesクラスタを管理する方法についていくつかの側面を説明してきました。しかし、クラスターの進化(アップグレード)というもうひとつの課題があります。
Kubernetesはクラウドネイティブ時代の「Linux」と呼ばれています。それは常にアップデートされ続け、よりモジュール化されています。Kubernetesの新バージョンをタイムリーに提供し続け、既存のクラスタのCVEの修正やアップグレードを行い、顧客のために大量の関連コンポーネント(CSI、CNI、Device Plugin、Scheduler Pluginなど)を管理する必要があります。
Kubernetesのコンポーネント管理を例に挙げてみましょう。まず、これらのプラグイン可能なコンポーネントをすべて登録・管理するための一元化されたシステムを開発します。
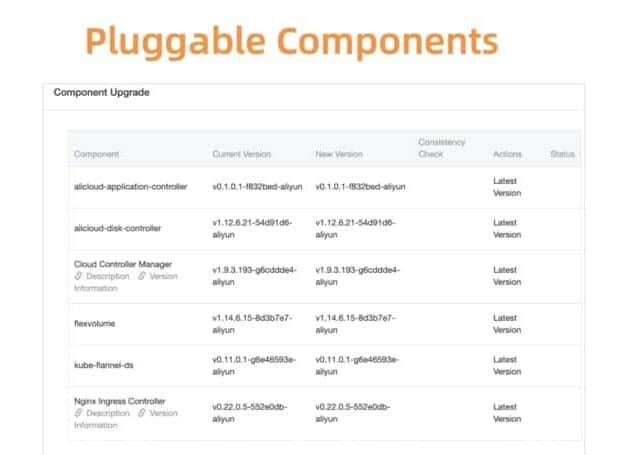
図5: Flexible and pluggable components
移行前のアップグレードが成功しているかどうかを確認するために、プラグインコンポーネントのヘルスチェックシステムを開発し、アップグレードごとのチェックとアップグレード後のチェックを行っています。
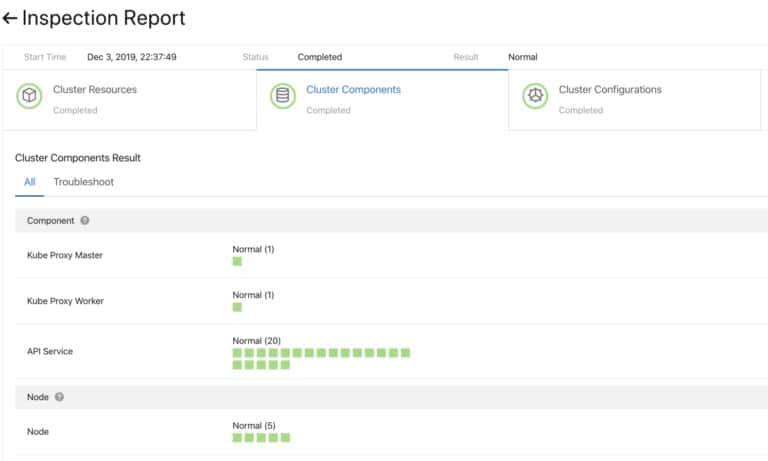
図6: Precheck for cluster components
これらのコンポーネントを迅速かつ確実にアップグレードするために、グレースケールデプロイメント(カナリアリリース)や一時停止などの機能を備えた継続的なデプロイをサポートしています。デフォルトのKubernetesコントローラでは、このユースケースでは十分に機能しません。そこで、プラグインとサイドカー管理の両方を含む、クラスタコンポーネント管理のためのカスタムコントローラのセットを開発しました。
たとえば、BroadcastJobコントローラは、各ワーカーマシン上のコンポーネントをアップグレードしたり、各マシン上のノードを検査したりするために設計されています。ブロードキャストジョブは、DaemonSetのように終了するまで、クラスタ内の各ノード上でポッドを実行します。しかし、DaemonSetは、ポッドがBroadcastJobで終了する間、常に各ノード上で長く実行されているポッドを保持します。また、Broadcastコントローラは、必要なプラグインコンポーネントでノードを初期化するために、新しく参加したノードでもポッドを起動します。2019年6月には、社内で使用していたクラウドネイティブのアプリケーション自動化エンジンOpenKruiseをオープンソース化しました。
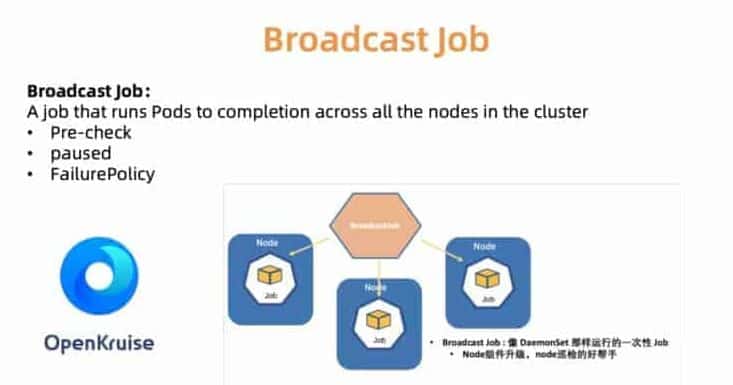
図7: OpenKurise orchestrates broadcast job to each node for flexible work
お客様が適切なクラスタ構成を選択できるように、サーバーレス、エッジ、Windows、ベアメタルのセットアップを含む、事前に定義されたクラスタプロファイルのセットも提供しています。今後、環境が拡大し、お客様のニーズが高まるにつれ、面倒な設定プロセスを簡素化するためのプロファイルを追加していく予定です。
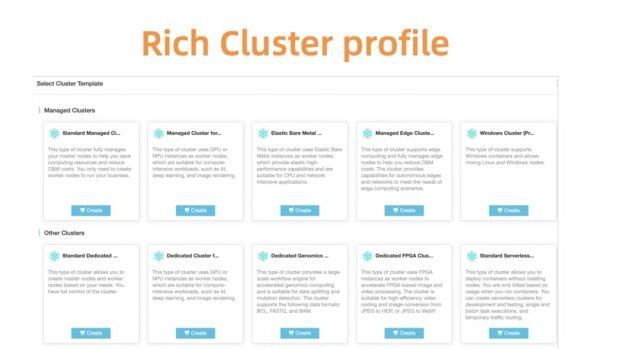
図8: Rich and flexible cluster profiles for various scenarios
Global Observability Across Datacenters
図9に示すように、Alibaba Cloudのコンテナーサービスは世界20リージョンで展開されています。このような規模を考えると、顧客クラスタにトラブルが発生した場合に迅速に対応して修正できるように、稼働中のクラスタの状態を容易に把握することが、ACKの重要な課題のひとつです。つまり、全リージョンの顧客クラスタからリアルタイムの統計情報を効率的かつ安全に収集し、その結果を視覚的に表示するソリューションが必要です。
図9: Global deployment in 20 regions for Alibaba Cloud Container Service
他の多くのKubernetes監視ソリューションと同様に、主要な監視ツールとしてPrometheusを使用しています。各メタクラスタについて、Prometheusエージェントは以下のメトリクスを収集します。
- ノードリソース(CPU、メモリ、ディスクなど)やネットワークスループットなどのOSメトリクス
- メタおよびゲストK8sクラスタのコントロールプレーン(kube-apiserver、kube-controller-manager、kube-chedulerなど)のメトリクス
- kubernetes-state-metricsやcadvisorなどのメトリクス
- etcdのディスク書き込み時間、DBサイズ、ピアスループットなど
このグローバルでのメトリクス収集の仕組みは、典型的な多層アグリゲーションモデルを用いて設計されています。各メタクラスタからのモニタデータは、まず各リージョンで集約され、そのデータはグローバルビューを提供する集中サーバに集約されます。これを行うために、Prometheusフェデレーションを使用しています。各データセンターには、データセンターのメトリクスを収集するPrometheusサーバーがあり、中央のPrometheusが監視データの集約を担当します。AlertManagerが中央のPrometheusに接続し、DingTalk、電子メール、SMSなどの手段でさまざまなアラート通知を送信します。可視化はGrafanaを使用して行われます。
図10では、監視システムを3つのレイヤーに分けることができます。
Edge Prometheus Layer
このレイヤーは、中央のPrometheusからもっとも遠い場所にあります。各メタクラスタに存在するエッジPrometheusサーバが、同じネットワークドメイン内のメタクラスタと顧客クラスタのメトリクスを収集します。
Cascading Prometheus Layer
カスケードPrometheusの機能は、複数の地域から監視データを収集することです。カスケードPrometheusサーバは、中国、アジア、ヨーロッパ、アメリカなどのより大きなリージョンに存在します。各大リージョンのクラスターサイズが大きくなると、大リージョンを複数の新しい大リージョンに分割し、常に新しい大リージョンごとにカスケードPrometheusを維持できます。この戦略を用いることで、柔軟な拡張と監視規模の進化を実現することができています。
Central Prometheus Layer
中央のPrometheusは、すべてのカスケードPrometheusサーバーに接続し、最終的なデータ集計を行います。信頼性を向上させるために、2つの中央Prometheusインスタンスを異なるAZに配置し、同じカスケードPrometheusサーバーに接続します。
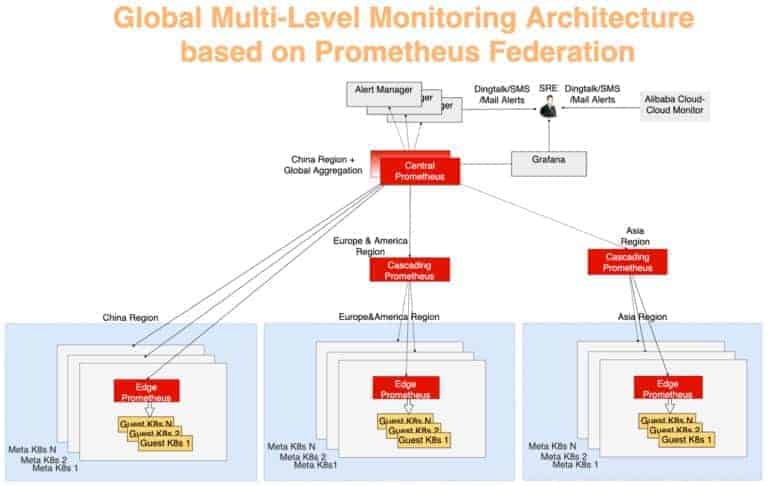
図10: Global multi-layer monitoring architecture based on Prometheus federation
要約
クラウドコンピューティングの発展に伴い、Kubernetesベースのクラウドネイティブ技術は、業界のデジタルトランスフォーメーションを促進し続けています。Alibaba Cloud ACKは、安全で安定した高性能なKubernetesホスティングサービスを提供しています。これは、クラウド上でKubernetesを実行するための最高のキャリアのひとつとなっています。Alibaba Cloudの背後にあるチームは、オープンソースとそのコミュニティを強く信じています。将来的には、クラウドネイティブ技術の運用と管理における私たちの洞察を共有します。
