こんにちは、もーすけです。
今回はしばらくの間、積み読となっていた「SRE サイトリライアビリティエンジニアリング」を読んだので、SREの生みの親が考えるその思想まとめます。(なんと購入したのは2018年3月で、3年4か月越しにまともに読むことになりました汗)
いまや、多くの企業でSREを名乗る職種がでています。 しかし、名前を変えただけのことも多くあると思っているので、SREの真髄はどこにあるのか?我々はなにを考えなければないらないのか?探っていきたいと思います。
書籍「SRE サイトリライアビリティエンジニアリング」について
有名な話なのでいまさら書くことでもないですが、SREという言葉を提唱したのはGoogleであり、O’Reillyから英語版で2016年3月に書籍がでました。2017年には、日本語版となって出版されました。 いまとなっては、その考えを取り入れて多くの企業でSREのロールを採用しています。
しかし、そのSREがなんであるのか?その真髄を理解するにはGoogleが提唱するものを理解する必要がありますが、それが大作として表現されたのがまさにこの書籍というわけです。 ただし、誤解してほしくないのは、「SREと名乗ること≠Google流でなければならない」ということです。語源を知ることはきっと皆さんにいいきっかけを与えると信じています。
GoogleのいうSREとは
まずは、Googleが提唱したSREとは何かを説明します。書籍の中には以下と書かれていました。
SREとは、ソフトウェアエンジニアに運用チームの設計を依頼したときにできあがるものです。
なかなか興味深いフレーズです。
運用メンバーにプログラミングをさせたとかそういうことではなく、ソフトウェアエンジニアに運用をやらせたというのは発想がすごいです。
ご存知のとおり、Googleといえばソフトウェアエンジニアのレベルはとても高いわけですが、実際にSREとして採用するソフトウェアエンジニアは、通常のGoogleのプロダクト開発のソフトウェアエンジニアと同じ採用プロセスをふむとも書かれていました。
(SREは)50-60%はGoogleのソフトウェアエンジニアです。もっと正確に言うなら、標準的なGoogleのソフトウェアエンジニアの採用手続きを通じて雇用された人物たちです。
なぜSREが必要だったのか?
SREがどんな人物たちなのかはわかりましたが、もっと重要なのは「なぜGoogleがこのような体制に挑戦したのか?」です。
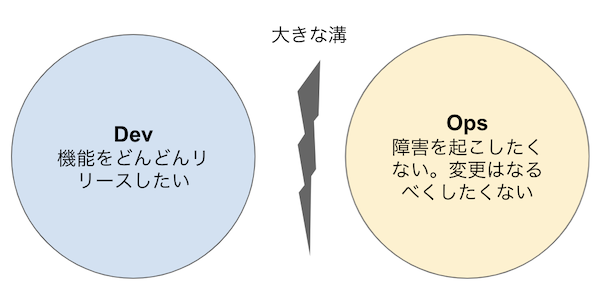
一般的にいわれるDevOpsを、Google流に突き詰めた形がSREであると考えます。 プロダクト開発において、運用チームと開発チームで衝突することがある、という話は聞いたことがあるし、現場でも経験したことある方が多いのではないでしょうか?
開発チームは、新しい機能をリリースし、ユーザがその機能を使ってくれるのを見たいと思います。 運用チームは、障害を起こしたくないと思います。多くの障害は何らかの変更によって引き起こされるものです。 この戦いをしている場合ではないと、Googleは考えたわけですね。 Googleでもこの問題を危惧するわけですから、他の会社でもまず間違いなく起きるものでしょう。
SREチームが大事にしていること
では、ソフトウェアエンジニアを採用して運用をやらせれば、解決でしょうか? 当然そんなことはなく、SREチームとして大事にしていることがいくつかあります。 本ブログでは、いくつかをピックアップしますが、より深く知りたい人はぜひ書籍を読んでみてくださいね。
エンジニアリングする時間の保証
みなさんの知っている運用チームは日々どんな仕事をしているでしょうか? 障害対応や、リリース作業などで追われている運用チームをわたしは見たことがあります。
原点をふりかえってみましょう。
なぜ、Googleはソフトウェアエンジニアに運用を担当させたのでしょうか?
なにを期待してソフトウェアエンジニアに運用を任せたのでしょうか?
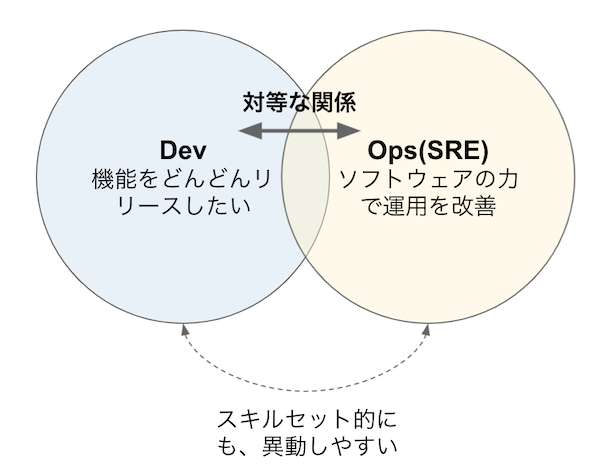
それは、もちろんソフトウェア開発によって運用を改善させるためです。 そして、プロダクトのスケールに運用のスケールが付いていくこと(しかも、運用作業量や人員がプロダクトのスケールに比例しないで)です。 SREの人たちが、日々の運用業務に追われていてはできないのもうなずけます。 仮にGoogleの凄腕エンジニアであっても、彼らがエンジニアリングに集中できる時間と体制が必要であることを忘れてはいけません。
GoogleはSREが運用作業にかける時間に対して50%という上限を設けています。残りの時間はコーディングスキルを使うプロジェクトの作業にあてることが求められています。そのため、SREが行う運用作業の量をモニタリングし、超過した運用作業をプロダクト開発チームへ差し戻します。
とんでもないフレーズがありますね。 「超過した運用作業をプロダクト開発チームへ差し戻します」とあります。 これは、見過ごせない一文と個人的に思っていますが、開発チームと運用チーム(SREチーム)のパワーバランスが対等であることを意味し、なぜソフトウェアエンジニアを運用担当にしているか?その意図を貫いていることがわかります。これこそが非常に重要なことではないかと個人的に思っています。
また、SREチームは、かなり早い段階で開発チームとコミュニケーションをとることも記載されていました。 完成したものを運用チームに引き継ぐ、という発想より、一緒に作り上げていくコミュニケーションのとり方を重要視しているのが読み取れました。
SLOの設定
開発チームとSREチームで、共通する指標を持つことがともに協力し合う重要なポイントです。 そこで、重要視しているのが「SLOの設定」とエラーバジェットという仕組みの組み合わせです。
SLOとは、Service Level Objectivesの略でサービスレベル目標です。 Googleでは、サービスの可用性の計測には、一般によく使われる稼働率ではなく、「リクエスト成功率」を使っているといいます。というのも、Googleのようなグローバルに分散されたサービスでは、だいたい世界中のどこかのリージョンではサービスを提供しているため、稼働率があてにならないとのことです。
数値的な指標を定めることの重要性は大きいです。 よくある伝統的な運用チームでは、障害が起きれば次は起こすなと怒られます。そしてどんどん保守的になります。 しかし、その障害での影響は、許容範囲内かどうかによって捉え方が異なると思います。 100%を目指すことは難しく、その分余計なコストがかかってしまうからです。 チームが、提供するサービスの目標があるのとないのでは大きく違います。
そして、Googleではエラーバジェットという仕組みを活用し、開発チームとSREはチームのお互いの利害を一致させています。開発チームは、プロダクトの開発速度がインセンティブとなり、SREチームはサービスの信頼性がインセンティブとなります。この相反する目的を、エラーバジェットという形で運用するわけです。
エラーバジェットとは、日本語的に「エラー予算」と読むとわかりやすいですね。 四半期毎で許容するリクエストエラー数を定義します。その予算を使い切ったら、新機能をリリースできないが、予算がある間は新機能をリリースできるということです。
この方式のなにがいいかというと、開発者側も安定したプロダクトを出すことにモチベーションがわくということです。テストを書くこと、品質のよいプロダクトを作ることで、より多くの新機能をリリースできるようになるわけです。SREチームにとっても、目標とする信頼性を確保できるので利害が一致します。
エラーバジェットと導入するにためには、当然「SLOの設定」が必須です。 数値目標がないことには予算は組めません。そしてそれを計測する手法が必要です。 本書の中では、その技術的な情報もたくさん紹介されています。
失敗から学ぶ、ポストモーテムの文化
なかなか聞き慣れない「ポストモーテム」という概念がでてきましたが、本書の中では次のように書かれています。一言でいうと、インシデント報告書でしょうか。ただ事象を説明したものというより、根本原因やそこから学んだ教訓を書き留めたものです。
インシデントとそのインパクト、その緩和や解消のために行われたアクション、根本原因(群)、インシデントの再発を避けるためのフォローアップのアクションを記録するために書かれるもの
SREチームでは、このポストモーテムをしっかり書くこと、そして共有することを重要視しています。
なぜ重要視しているのでしょうか?(考えてみましょう!)
いくつかの側面があるかなと思いますが、しっかり根本原因を潰すことはSREの思想に非常にマッチしているのです。 暫定対応で一時的な処置をしただけの場合、また起こるかもしれません。 この積み重ねは運用作業を50%以下に抑えることから遠のく結果をもたらします。 また、根本原因を潰せるように高いソフトウェアエンジニアリングのスキルを持っている人がSREをやっているわけです。
書籍の中では、サンプルのポストモーテムも記載されているので、参考になるはずです。
SREの育成
また、組織的なことも多く取り組みがあります。 序盤の方でも書きましたが、SREは採用が難しいです。なにせ、Googleのソフトウェアエンジニアの採用試験をパスし、かつ運用に必要なシステムエンジニアリングの知識も持ち合わせていなければならないからです。書籍には明確に書かれていませんでしたが、SREはプレッシャーとの戦いにもなるはずです。おそらくテクニカルなスキル以上に、性格的な面もおおきく関わるのかなと思います。 そのため、育成することは非常に重要な課題といえます。
特徴的だったことは、その教育方法が体系化されていることでした。 チームに参加してからの時間軸とともに、実践的なことと思考的なことを分類して、その手法がかかれています。 単純に、先輩についてOJTするなどではなく、ロールプレイングやリバースエンジニアリングなど実環境の対応をする下準備を伴って徐々にスキルアップしていくことを重要視しているようです。
さいごに
本書を読んで、自分たちが運用チーム(あるいはインフラチーム)を作るときに、なにを大事にして組織を作ったらいいかのヒントになると感じています。逆に言うと、プロダクトスケールを見込んでいるからこそ、ソフトウェアエンジニアに運用をさせることを踏み切ったわけで、自分たちのプロダクトの特性次第で大きく考え方も変わってくると思っています。
また、GoogleのSREチームが作り出したソフトウェアにBorgやBorgmonといったものがありますが、これらはKubernetesやPrometheusという形でオープンソースとして我々は簡単に利用できる時代にいます。 自分たちが理想としている運用を作り上げるための武器やツールとしては成熟してきているのも事実です。そのなかで我々がなにを考えて運用チームを作っていくべきかは腕の見せ所ですね。
運用チームを担当している人、プロダクト開発チームを担当している人、ぜひ一度この書籍を読んで自分たちのチームのありかたの模索、そしてエンジニアとしてのキャリアの選択として参考にしてみるといいと思います。
